How It Works
Dataset Construction & Error Taxonomy
ArtiFact is built through a 5-step Extract-Transform-Load (ETL) pipeline that collects, structures, normalizes, and deduplicates records from three institutions, then supports downstream tasks including error detection and semantic querying.
Data Collection & Downstream Tasks
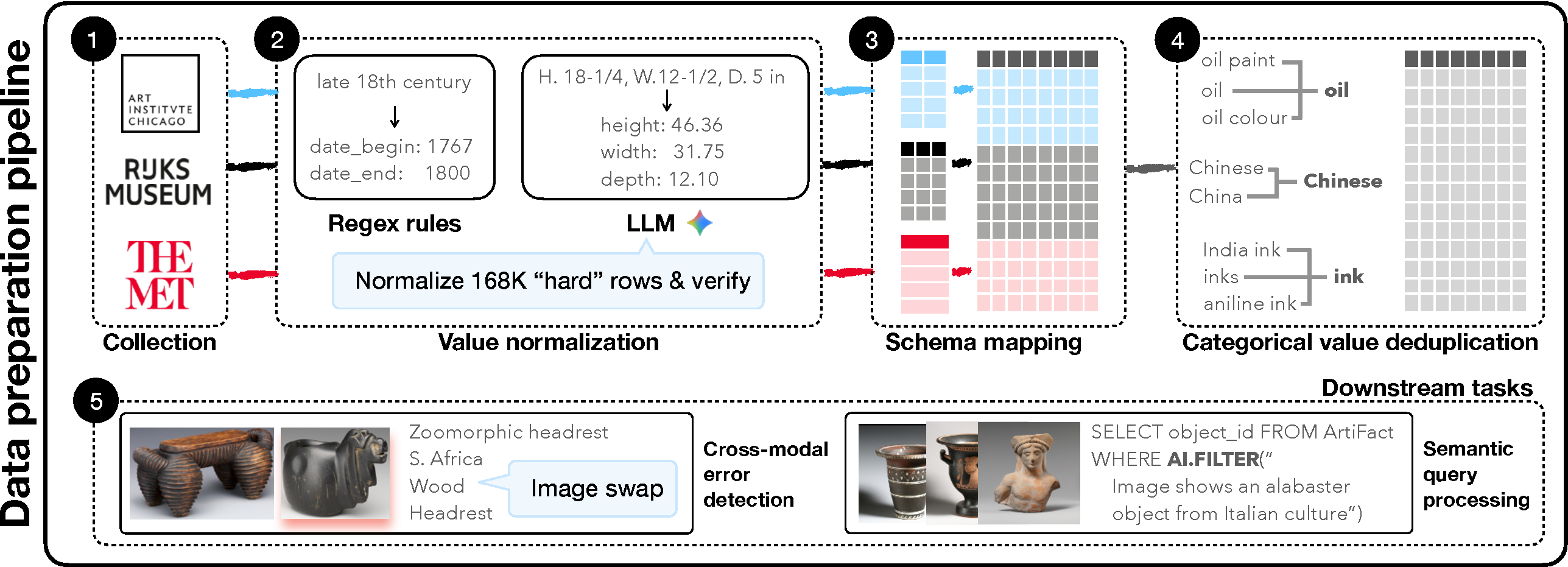
Overview of the dataset generation process: an ETL pipeline ① collects, ② structures & prepares, ③ maps to a shared schema, and ④ performs semantic data unification across three cultural heritage institutions; the preprocessed dataset supports ⑤ downstream tasks including cross-modal error detection and semantic query processing.
